RSS-Bridge; Smol Wonder; Flow
Today, we follow up on the journey from Inoreader to FreshRSS with a look at a cool project that turns any site into an RSS feed. Then, we check back in on using SmolLM3 for a different kind of local inference. And, finally, we take a look at an alternative to the Arc browser.
TL;DR
(This is an LLM/GPT-generated summary of today’s Drop using SmolLM3-3B-8bit via MLX and a custom prompt.)
- RSS-Bridge summary (https://rss-bridge.github.io/rss-bridge/General/Project_goals.html)
A PHP tool that scrapes website content into RSS feeds, with over 500 pre-built bridges for sites like YouTube and GitHub. The author created a custom bridge for the Censys blog using a CSS selector, allowing FreshRSS to access the content. - Smol Wonder summary (https://codeberg.org/hrbrmstr/gists/src/branch/main/2025/ner.py)
A project analyzing POTUS’ social media posts to assess his health, using JavaScript Compromise for content extraction. SmolLM3 was tested for NER and JSON generation, successfully producing structured JSON data from 4,400 posts. - Flow summary (https://flow-browser.com)
A Chromium-based browser with features like Spaces, command palette, ad-blocking, and time-based tab archiving, replacing Arc temporarily after Atlassian’s acquisition. The developer remains cautious about potential AI integration by the project’s creators.
RSS-Bridge

We talked about FreshRSS the other day, and I’ve been using it as my primary feed reader since setting it up, save for the handful of programmatic feeds (for sites without RSS) I’ve been relying on Inoreader to generate for me.
I had just enough time to poke at open-source solutions for said use case and settled on RSS-Bridge (GH). It’s a clever tool that acts as a sort of “universal translator” between feed readers and website content. This (ugh) PHP application visits websites on your behalf, scrapes their content, and transforms it into proper RSS feeds you can actually subscribe to.
It ships with over 500 specialized scripts called bridges, covering everything from YouTube and Reddit to GitHub releases and weather alerts. Each pre-built, site-specific bridge knows exactly how to extract the right content from its target site and package it as a clean, readable feed.
Their bridge inventory does not have a script for the new Censys blog (one of the programmatic ones I’ve relied on Inoreader for), but with the CSS Selector bridge, I was able to create one using basic web scraping. All I had to do was find the right CSS selector:

and then set it up in the app:
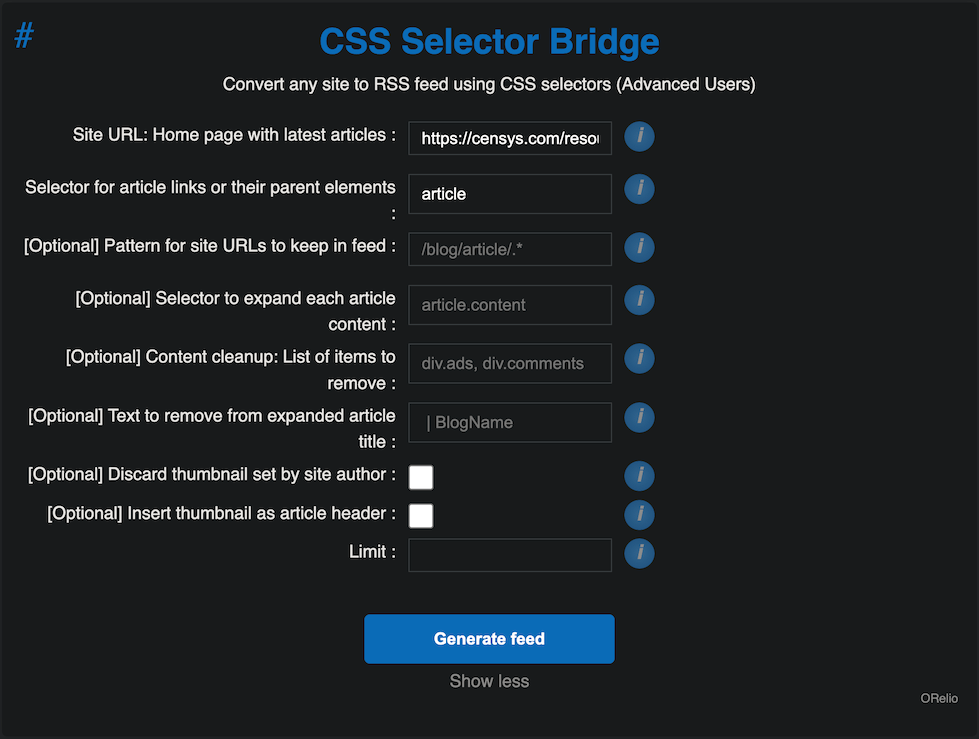
copy the Atom feed link, and add it to FreshRSS.
You can even try it out at their public instance, or run your own server if you prefer (the Docker container works great).
The tool is flexible enough to be used as a general way to turn almost any website into “data” (and, if you are not a fan of XML, there’s a JSON feed format for any programmatic feeds).
Smol Wonder
(This is a slightly longer-form version of what I posted on Mastodon and Bluesky yesterday, so you can likely skip it if you didn’t catch it there.)
I continue to tinker on my project to try to use POTUS’ social media posts to determine whether he’s dead or debilitated (it started the recent weekend he likely had a cardiovascular episode). If he is incapacitated, you can be sure handlers will use the feed to further brainwash and entrench his followers before revealing any severe situation with him.
As noted in the Thursday Drop, the project already generates an “Authenticity Score”, partly based on what it was able to extract via the JavaScript Compromise library. While it works well for the existing components it extracts, the heuristic-based named-entity recognition (NER) and extraction leaves much to be desired.
I decided to see if SmolLM3 (the Apple Silicon-compatible MLX version) was up to the NER task, and a quick interactive test showed it was. Since I’m not going to cut/paste POTUS bleets every time he excretes one of them, I also had to see if SmolLM3 was up to the task of emitting useful JSON (if so, it would mean we can wrap this up in a nice script). And, thankfully, it was!
You can see the whole (ugh) Python script on Codeberg, but this is the key part:
system_prompt = """/no_think
You are a JSON generator.
You are a JSON generator.
Extract ALL people, places, and topics from the provided input.
Please use structured JSON for the output:
{
"people": [ "string", "string", etc. ],
"places": [ "string", "string", etc. ],
"topics": [ "string", "string", etc. ],
}
Return only JSON inside these markers:
<json>
{ ... }
</json>
Important: Your entire output must be a single valid JSON object.
Do not add comments, explanations, or text outside the JSON braces.
If you cannot comply, output {}.
"""
(For whatever reason it works better repeating the “You are a JSON generator.” bit.)
Here’s a random sample from ~4,400 posts:
$ duckdb posts_processed.db
🦆>FROM processed_posts
SELECT
json_data
WHERE json_data != '{"people": [], "places": [], "topics": []}'
USING SAMPLE 10 ROWS;
┌────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ json_data │
│ varchar │
├────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ {"people": [], "places": [], "topics": ["autopen", "president"]} │
│ {"people": ["John Yoo"], "places": [], "topics": ["presidency", "American people", "agenda", "court", "win"]} │
│ {"people": [], "places": [], "topics": ["Happy Mother's Day", "Goodnight"]} │
│ {"people": ["Kid Rock", "Bill Maher", "Legendary Dana White"], "places": ["White House"], "topics": ["meeting", "fav… │
│ {"people": [], "places": [], "topics": ["Hannity", "Trump", "Bill", "massive wins", "watch"]} │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
I still need to do some post-processing (as one usually has to with NER processes), but it works very well and is very fast on the M4 Mini. I could also likely significantly improve the prompt, but it works well-enough for the intended purposes.
The Ollama org and community are still way behind on tweaking the Ollama code to support this model (I guess trying to grift off of the commercial “AI” bubble was/is more important?), so Python + MLX is the way you’ll have to go if you’re on Apple Silicon. The CUDA version of SmolLM3 works just fine on supported hardware.
I wish more attention was paid to these practical, helpful, and nigh harmless uses of these modern models vs. the mass pretending that their chatty, generative counterparts are worth what everyone in power seems to be willing to sacrifice to use them.
Flow

The Arc browser has been thrown a lifeline (at least temporarily) with Atlassian acquiring The Browser Company. Everything Atlassian touches turns to Jira (i.e., 🗑️), and there’s too much general frenzy over making commercial “AI” + Chromium homunculi for me to believe Atlassian won’t just rm -rf the Arc source and focus solely on the trAIsh heap that is Dia.
The few independent rendering engine/browser projects are all moving forward well, but none of them are ready for daily use, and there’s no way you’ll get me to run any app Mozilla touches, so I poked around (again) to see what’s out there, and came across Flow (GH). It’s Chromium-based (so, far from ideal, but it is what it is) and feels very Arc-like.
It has Spaces, a command palette, built-in ad++ blocking, sidebar tabs (which can be collapsed), time-based tab archiving, Manifest V2 extension compatibility, Cmd-Shift-C URL copying (I rely heavily on that particular feature in Arc).
It does not have split tabs, pinned tabs, or favorites (I use Raindrop anyway, but y’all do seem to like your favs built-in), and split tabs do not seem to be on the menu (yet), but it has just enough for me to switch when Atlassian eventually kills Arc.
Now, Multibox Labs (the makers of Flow) has an “AI” chatbot (https://chat.iamevan.dev/), so a very wary (and, weary) part of me also suspects they’re going to slopify Flow into another “AI” homunculus. I do hope my cynicism is not warranted, especially since Google was thrown a nice bone by the system and will likely find a way to force their “AI” into Chromium, too, at some point.
FIN
Remember, you can follow and interact with the full text of The Daily Drop’s free posts on:
- 🐘 Mastodon via
@dailydrop.hrbrmstr.dev@dailydrop.hrbrmstr.dev - 🦋 Bluesky via
https://bsky.app/profile/dailydrop.hrbrmstr.dev.web.brid.gy
☮️

Leave a reply to hrbrmstr Cancel reply