cli-stash; llparse & llhttp
There are three resources, today, but it didn’t make sense to separate out llhttp from the llparse section.
TL;DR
(This is an LLM/GPT-generated summary of today’s Drop. Ollama and MiniMax M2.1.)
- cli-stash is a Bubble Tea-based micro-TUI that streamlines shell command management by allowing efficient saving and retrieval from history using ctrl-a, with fuzzy search and smart sorting based on usage frequency (https://github.com/itcaat/cli-stash)
- llparse is a domain-specific language in TypeScript that compiles parser descriptions into optimized C code, and its practical application llhttp reimplemented Node.js’s http_parser in ~1,400 lines of TypeScript while achieving 156% faster parsing performance (https://github.com/nodejs/llhttp)
cli-stash
One item I forgot from the “daily drivers” post for 2026 was McFly. It “replaces your default ctrl-r shell history search with an intelligent search engine that takes into account your working directory and the context of recently executed commands.” I don’t think a waking hour in front of a keyboard-laden glowing rectangle goes by without me invoking it at least 10x. It’s great.
There are other tools such as atuin that let you accumulate shell history from all your systems and sessions, but the corporate infosec wonk in me shudders at the thought of doing more than testing those out (I’m actually shocked we haven’t seen a breach attributed to that tool yet, but then most breaches aren’t detected and the ones that are usually aren’t reported).
I consider McFly as a “needle in a haystack” finder, so that’s how I use it. And, that is not always optimal. There are times I just don’t want to type a specific command, but want a quick way to get to it. I’m one of those old-school CLI folks who kinda refuses to overly alias or script things, mostly to ensure I can type what I need in any environment, including foreign ones where my scripts and aliases might not exist, and getting them there would be painful.
cli-stash fills a nice gap. It’s a Bubble Tea-based micro-TUI that I can see further streamlining my daily workflows by letting me efficiently save and manage shell commands directly from my history using ctrl-a. The fuzzy search feature offers real-time filtering, ensuring you never have to manually hunt through logs again.
Like McFly it keeps the most relevant shortcuts at the ready via smart sorting based on usage frequency.
The feature list is compact, and the micro-TUI is well-implemented, so you don’t really need to read the README, but it does provide a great overview. The config is in ~/.stash/commands.json, so you can even populate it directly without doing the ctrl-a dance.
This one’s a keeper!
llparse & llhttp
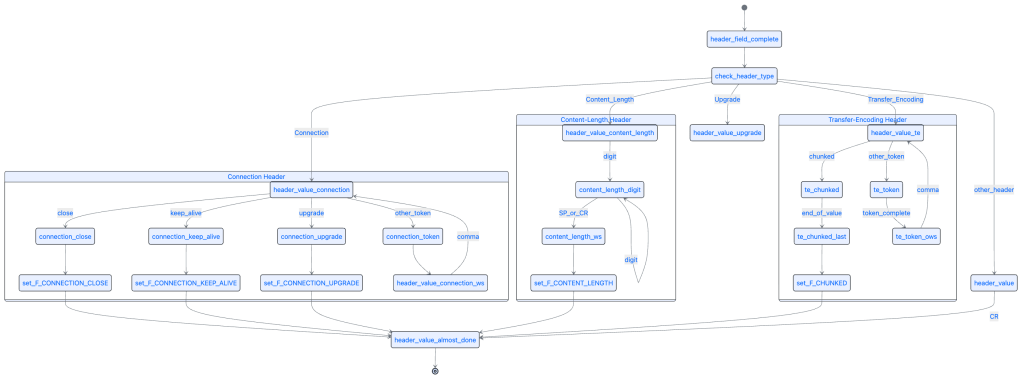
(It was super-fun digging into both resources, and I’m sad I did knot know about them before this week.)
Also, since this essentially builds state machines, I threw together some Mermaid diagrams of the various llhttp bits.
Node.js has always been fundamentally about HTTP (duh?). Ryan Dahl built the original platform specifically to create high-performance asynchronous web servers, and at its core sat http_parser — a hand-optimized C library that parsed HTTP requests and responses with minimal memory overhead (around 28-40 bytes per connection). The parser worked well for years, but it eventually became nearly impossible to maintain.
Adding a single new HTTP method required careful surgery through approximately 2,500 lines of hand-unrolled, manually-optimized C code. Every optimization was bespoke and very change risked performance regressions or introducing subtle parsing bugs. The code prioritized execution speed over human comprehension, and anyone who’s inherited that kind of codebase knows exactly where this story goes.
Fedor Indutny, a longtime Node.js core contributor (and the person behind several other Node internals), recognized this wasn’t sustainable. Multiple attempts to refactor http_parser over the years had failed because any structural improvement inevitably degraded performance. The tight coupling between what the parser did and how it did it efficiently meant you couldn’t touch one without breaking the other.
Indutny’s insight was to stop writing parsers and start writing a parser generator. The result was llparse, a domain-specific language implemented in TypeScript that describes parsing states as a graph, then compiles that graph down to optimized C code (or optionally LLVM IR bitcode).
The approach inverts the maintenance burden. Instead of manually implementing state machine transitions and then hand-optimizing them, you describe what you want to match in a declarative API. The compiler handles optimization automatically, including multi-character matching and state merging. When parsing HTTP methods like POST, PUT, and PATCH, the generated code automatically recognizes that all three share a leading ‘P’ and combines the initial states rather than maintaining three separate code paths.
The compilation step also enables static analysis that was previously impossible. llparse can verify that the state machine graph contains no infinite loops, that all input ranges are correctly reported, and that error conditions are properly handled. These guarantees come essentially free since they’re verified at compile time rather than requiring exhaustive runtime testing. (Anyone who’s tried to write comprehensive tests for a hand-rolled parser knows how much coverage you’re actually missing.)
llhttp is the practical application of all this theory. It’s a complete reimplementation of http_parser written in about 1,400 lines of TypeScript describing the parser logic, plus roughly 450 lines of C helper functions. Compare that to the original’s 2,500+ lines of pure C.
The performance results were surprising even to Indutny, as llhttp parses HTTP approximately 156% faster than the hand-optimized original. The generated code uses techniques like extensive goto statements and aggressive inlining that would be maintainability nightmares if written by hand but are perfectly acceptable as compiler output that humans never need to read or modify.
Node.js adopted llhttp experimentally in v12 (late 2018), made it the default in subsequent versions, and eventually archived http_parser entirely in November 2022. The old parser is now explicitly deprecated, with the README directing users to llhttp.
For security researchers and anyone analyzing HTTP-layer exploits, the key shift here is that llhttp’s explicit state machine representation makes it easier to reason about edge cases like request smuggling(attacks that often exploit subtle disagreements between parsers about where one request ends and another begins). llhttp includes extensive “lenient mode” flags that can relax strict parsing for compatibility with malformed clients, but each flag comes with explicit security warnings about the attack surfaces it opens. If you’re probing Node.js infrastructure, knowing which lenient modes might be enabled (and what parsing behaviors they permit) matters.
The broader lesson is that compiler-generated parsers are fundamentally about making the parsing behavior auditable in ways that hand-written state machines never were. llparse itself is MIT-licensed and maintained under the Node.js organization on GitHub, so the same approach could work for other line-oriented protocols where the current implementation involves fragile hand-maintained state machines.
Understanding llhttp’s parsing decisions is now table stakes for analyzing HTTP-layer attacks against anything running on modern Node.js.
FIN
Remember, you can follow and interact with the full text of The Daily Drop’s free posts on:
- Mastodon via
@dailydrop.hrbrmstr.dev@dailydrop.hrbrmstr.dev - Bluesky via
<https://bsky.app/profile/dailydrop.hrbrmstr.dev.web.brid.gy>
☮️

Leave a comment