DuckDB 1.3.0; jOOQ; Karakeep
To remember something, one needs to first collect and store said something. So this issue is all about databases ops and the satisfying practice of collecting those digital breadcrumbs scattered across the internet, ready to be retrieved when inspiration (or desperation) strikes.
TL;DR
(This is an LLM/GPT-generated summary of today’s Drop using Ollama + Qwen 3 and a custom prompt.)
- DuckDB 1.3.0 introduces external file caching for faster cloud data access and recursive query improvements for complex data analysis (https://duckdb.org/2025/05/21/announcing-duckdb-130.html)
- jOOQ provides type-safe SQL queries in Java/Kotlin and offers an online SQL translation tool for multiple dialects (https://www.jooq.org/)
- Karakeep is an open-source personal knowledge management platform that uses AI for organizing digital content with full control and privacy (https://karakeep.app/)
DuckDB 1.3.0: Making Analytics Faster and Easier

While I may have been DoS’d by work-related travel, the DuckDB folks have been hard at work making one of the most important tools released in the past few years even spiffier than it already is (ref: 1.3.0 release & recursive query improvements).
DuckDB 1.3.0 was released on May 21, 2025 and include some ace improvements that make data analysis faster and more practical for folks working with large datasets.
The most significant improvement addresses a common problem: slow performance when working with data stored in the cloud or on remote servers. Previously, DuckDB had to reload entire datasets from sources like Amazon S3 or other cloud/web-accessible storage every time someone ran a query, creating delays and unnecessary network traffic. The new external file caching system solves this by intelligently storing frequently used remote data in memory. This change delivers immediate benefits for teams running multiple queries against the same datasets. Performance testing shows query times dropping by 75 percent on repeated runs, transforming routine analytical work from time-consuming operations into near-instantaneous responses.
If you need to analyze network effects, trace relationships, or work with graph-like data structures, DuckDB 1.3.0 also introduces enhanced recursive query functionality that enables more sophisticated analytical operations. Recursive queries let us work with hierarchical data structures, such as organizational charts, social networks, or supply chain relationships, but traditional implementations have been limited and inefficient.
The new approach addresses these limitations by allowing queries to update and refine results as they progress, rather than simply accumulating more data with each step. This is a pretty yuge change that makes complex analytical operations practical within SQL, reducing the need for specialized tools or custom programming. These improvements enable analysis that were previously impractical or impossible using standard database queries.
Several new quality-of-life enhancements reduce the complexity of working with data files. The command-line interface can now directly query data files without requiring database setup (I’ve been waiting for this with bated breath), letting us immediately explore CSV, Parquet, or JSON files by simply pointing DuckDB at the file location. The system also includes improved error handling through new TRY expressions that gracefully manage calculation errors, returning null values instead of stopping query execution when encountering problematic data. This makes exploratory analysis more robust when working with inconsistent or incomplete datasets, and removes one more reason to incorporate any other tooling for data ops.
Enhanced support for defining complex data structures (STRUCTs) means we have way more flexibility to meet evolving analytical requirements without requiring.
Internal improvements include completely rebuilt file reading and writing systems that handle data more efficiently and support a broader range of file formats. New compression techniques automatically select optimal storage methods based on data characteristics, reducing storage requirements and improving query performance.
Enhanced spatial analysis capabilities provide specialized operations for geographic data that can deliver performance improvements of up to 100 times! for location-based queries, making geographic analysis practical for larger datasets.
This is definitely a major release with tons of features to explore. Make sure to keep an eye on the roadmap, because DuckDB extensions are about to become democratizied, and data confidentiality will also be a welcome new feature.
jOOQ: Type-Safe Database Queries & Universal SQL Translation

jOOQ (GH) takes a spiffy approach to database programming that bridges two traditionally separate worlds: the object-oriented nature of Java/Kotlin (and other languages) and the relational structure of SQL databases. Think of it as a translator that speaks both languages fluently, letting us write database queries in code that feel natural while preserving the full expressiveness of SQL.
This framework helps remove disconnect between how we tend to think about data in objects versus how databases actually store and manipulate that data. Traditional Object-Relational Mapping (ORM) frameworks try to hide SQL entirely, but this often creates more problems than it solves because SQL is actually quite powerful and expressive. jOOQ takes the opposite approach: instead of hiding SQL, it embraces it and makes it safer and more accessible through Java.
Here’s how this works in practice. When you set up jOOQ with your database, it examines your actual database schema and generates Java/Kotlin code that mirrors your tables, columns, and relationships. This means that when you write a query, your IDE can help you with autocompletion, and the compiler can catch errors before your code ever runs. If you try to reference a column that doesn’t exist or join tables incorrectly, you’ll know immediately rather than discovering the problem at runtime. While I have not performed super extensive tests, basic ones show that it’s definitely possible to take the current Java-centric output and have our AI overlords (espcially Claude 4) whip up some TypeScript-equivalent code.
For a freemium tool with some usae limitations when used in FOSS contexts, there are scads of GitHub ⭐️ and a very actrive community.
If you detest Java as much as I do, but also have a need to translate between SQL dialects, then one of the most immediately practical demonstrations of jOOQ’s capabilities is the online SQL Translation tool. This web-based interface showcases the deep understanding of SQL dialects that jOOQ has developed over years of supporting diverse database systems. The translation capability isn’t just a separate feature, as it emerges naturally from jOOQ’s core architecture, since the library must parse, understand, and generate SQL for multiple database systems.
Just input SQL written for one database system and have it automatically translated to work with another, complete with dialect-specific optimizations and syntax adjustments. The tool offers remarkable granular control over formatting preferences, from keyword capitalization to join style conventions, reflecting the nuanced understanding of SQL variations that jOOQ embodies.
I’m likely only going to ever use the online tool, but definitely appreciate the continued evolution of this tooling (it’s been around since ~2009!).
Karakeep: Hoard All The Things
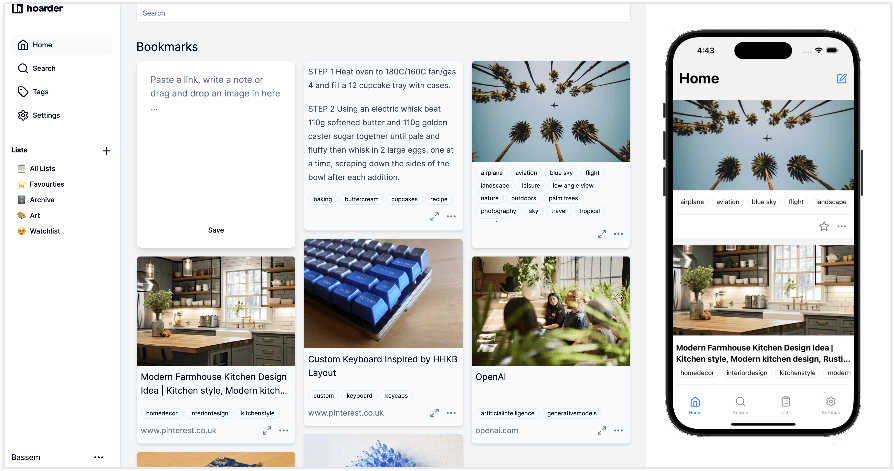
Since Karakeep’s value prop will be immediately grokable by y’all, let me respect your intelligence + time, and also take a mo’ to exercise the Smart Brevity muscle I noted in a few previous Drops.
Karakeep (GH) is an open-source personal knowledge management platform that turns digital chaos into organized, searchable archives. Born from the ashes of Hoarder after a 2025 trademark dispute, this self-hosted application (optionally) uses AI to automatically categorize bookmarks, notes, images, and PDFs while preserving complete control over data.
Why it matters
Privacy-conscious folks finally have a comprehensive solution that combines powerful AI organization with zero data collection. The self-hosting model means your digital knowledge stays yours. There are no cloud dependencies, no corporate surveillance, just intelligent archival under your control.
Core features
AI-powered organization: Automatically tags and categorizes content using ChatGPT or local Ollama models, eliminating manual filing.
Universal capture: Bookmarks links, stores notes, preserves images and PDFs with automatic metadata extraction and OCR text recognition.
Future-proof archival: Full-page preservation via Monolith prevents link rot, while youtube-dl integration archives videos permanently.
Cross-platform ecosystem: Native iOS/Android apps with sharing extensions, Chrome/Firefox browser extensions, and comprehensive API access.
Technical excellence
The development infrastructure demonstrates enterprise-grade quality: comprehensive CI/CD pipelines, TypeScript throughout, automated testing, and modern tooling with pnpm and Turbo. The codebase transparency addresses recent privacy concerns, as everything is now auditable, and nothing is hidden.
The big picture
Karakeep represents the evolution of personal knowledge management: intelligent automation without surveillance capitalism. For folks who refuse to compromise between convenience and privacy, this platform delivers both.
Go deeper: The project’s transition from Hoarder showcases mature open-source governance, while its Arabic etymology (“كراكيب” — “valuable clutter”) perfectly captures its mission of transforming digital chaos into organized wisdom.
FIN
Remember, you can follow and interact with the full text of The Daily Drop’s free posts on:
- 🐘 Mastodon via
@dailydrop.hrbrmstr.dev@dailydrop.hrbrmstr.dev - 🦋 Bluesky via
https://bsky.app/profile/dailydrop.hrbrmstr.dev.web.brid.gy
☮️

Leave a comment