ChatDB; DataTrove; Envirowashing AI
Yep, there has been sufficient news in the AI space to warrant yet-another semi-infrequenty looksie by the Drop.
TL;DR
(This is an AI-generated summary of today’s Drop.)
- ChatDB: ChatDB’s Parquet AI allows users to upload Parquet files and query them using natural language, generating SQL queries and results directly in the browser. It uses WebAssembly and Llama-3-70b AI for processing. However, it is not recommended for sensitive data due to privacy concerns. ChatDB’s Parquet AI
- DataTrove: Hugging Face’s DataTrove is a platform-agnostic framework designed to simplify data processing tasks for AI pipelines. It includes customizable pipeline blocks for tokenization, deduplication, and more, supporting various input/output sources. DataTrove
- Envirowashing AI: AI technologies are being used to address environmental challenges, such as flood forecasting, weather prediction, and sustainable flights. These projects aim to improve accuracy and efficiency in predicting natural events and reducing environmental impacts. Two Minute Papers overview
ChatDB
Despite the rants of vocal detractors (which includes your friendly neighborhood hrbrmstr), there are promising and practical uses of AI. Now, I’m pretty passionate about democratizing “data science”; and, one aspect of said democratization is the ability to query data in a way that is natural to the average human. Since we now have an increasingly more proficient set of models that can do human blathering-to-SQL translation, letting folks ask literal questions of data and have double-check-able SQL calls generated, and query results provided, we’re starting to do more than just inch forward in the democratization process.
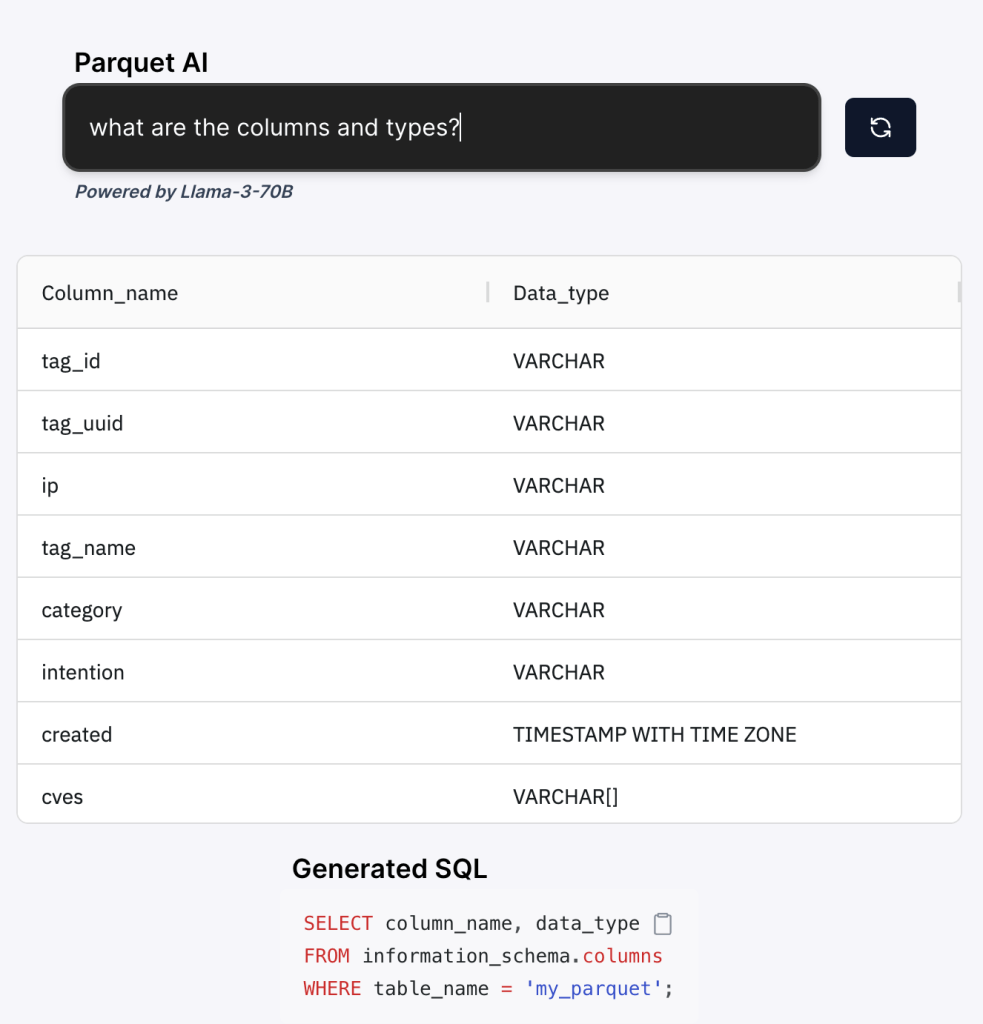
I came across ChatDB’s Parquet AI, which is a free, [almost] everything done in-browser web app that lets you upload a Parquet file (they have a CSV sibling utility), and then ask an English (it may support other human languages) question, see the SQL, and review the results.
This is the same ChatDB that that’s behind Natural-SQL-7B.
The service tries to hand wave away and mask that it sends dataset metadata to their server (protip: gzip data blobs == obfuscation, not privacy), but there’s no way it can have the server figure out SQL queries without some context. i.e., don’t use this tool on sensitive data.
Under the hood, ParquetAI leverages WebAssembly (I have no idea why they didn’t just say “DuckDB WASM”) and Llama-3-70b AI (which they fail to note on the app site exists on their servers). The resulting process is simple:
- it detects column types and names in your Parquet.
- it then prompts Llama-3-70b AI to generate SQL based on your natural language query.
- it then xecutes the SQL in your browser directly against the Parquet without data leaving your device.
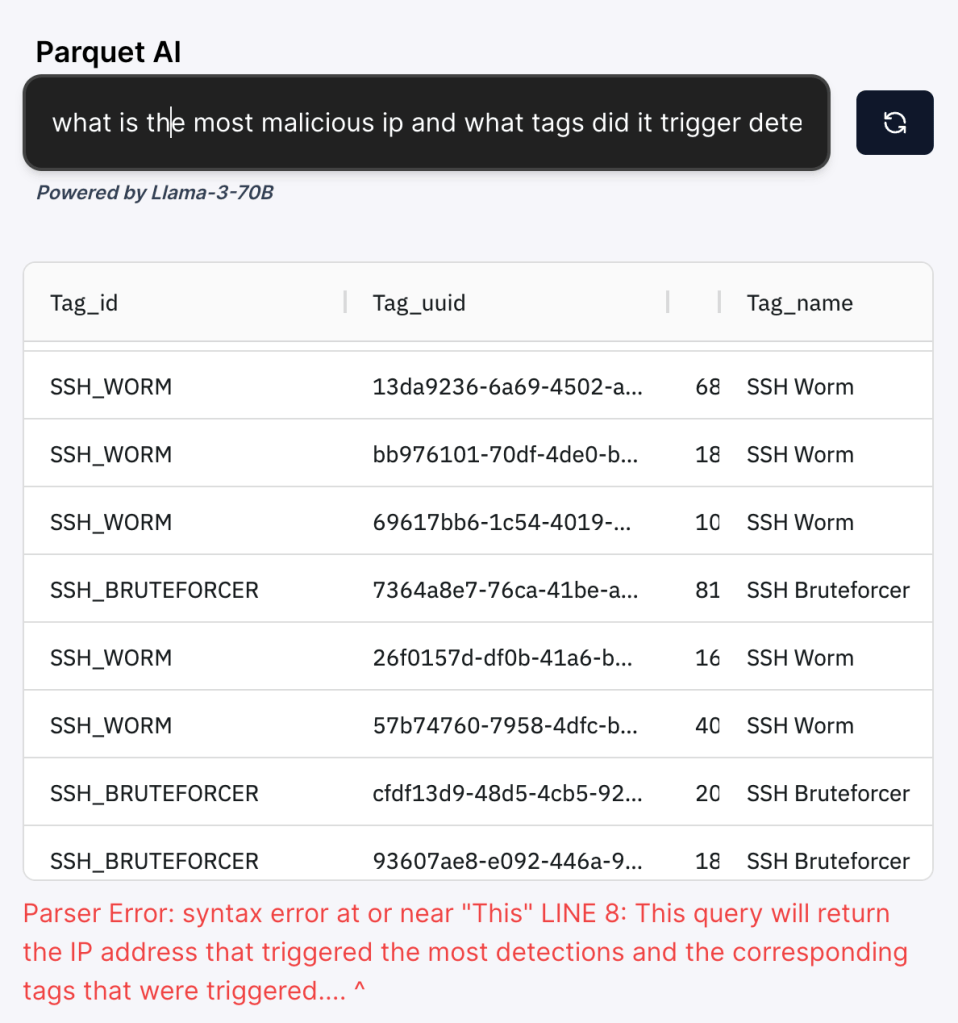
I gave it a small Parquet file (section header) and asked: “What is the most malicious ip and what tags did it trigger detections on?” The results came up but there were “issues” on the LLM side which prevented me from seeing the SQL.
It did fine on virtually all other queries:
> How many unique IPs are in this dataset?
SELECT COUNT(DISTINCT ip)
FROM my_parquet;
(490289)
> What are the bottom 20 least prevalent unique tags
SELECT tag_name, COUNT(*) as count
FROM my_parquet
GROUP BY tag_name
ORDER BY count
LIMIT 20;
> How many records are there of unique ip addresses with malicious intentions
SELECT COUNT(DISTINCT ip)
FROM my_parquet
WHERE intention = 'malicious';
Ultimately, it’s a decent demo of what’s possible, and may help you get some buy-in to experiment with models like natural-sql-7b.
NOTE: Please do not confuse this with Chat2DB, which is something we’ll cover at a later date.
DataTrove

I’m pretty sure we all 💙 Hugging Face, and their spiffy DataTrove project is platform-agnostic framework created to simplify data processing tasks as they pertain to AI processing pipelines. The project provides a set of customizable pipeline processing blocks that can handle various stages of data manipulation, from extraction to deduplication. They (essentially) codified some repeatable steps to remove the boring and tedious work you’d normally have to code up yourself to get inputs ready for AI processing.
Their README is decent, so I could just leave you there, but I think this might be a slightly less time-consuming overview of what’s in the tin:
- pipeline blocks:
- tokenization: the
tokenize_c4.pyscript reads data directly from HF’s hub to tokenize the English portion of the C4 dataset using thegpt2tokenizer. - minhash deduplication: the
minhash_deduplication.pyscript provides a full pipeline to run minhash deduplication of text data. - sentence deduplication: the
sentence_deduplication.pyscript offers an example to run sentence-level exact deduplication. - exact substrings: the
exact_substrings.pyscript runsexactsubstr
- tokenization: the
- task management: DataTrove keeps track of task completion by creating markers (fancy word for “empty files”) in the
${logging_dir}/completionsfolder. if some tasks fail, you can relaunch the same executor, and DataTrove will only rerun the incomplete tasks. it is crucial not to change the total number of tasks when relaunching, as this affects input file distribution and sharding. - input/output sources: DataTrove supports a diverse array of input/output sources through
fsspec. Paths can be provided in several ways, including:- as a simple string, e.g.,
/home/user/mydir,s3://mybucket/myinputdata,hf://datasets/allenai/c4/en/ - as a tuple of a string path and a fully initialized filesystem object.
- as a simple string, e.g.,
Note that each pipeline block processes data in HF’s DataTrove document format (which helps simplify their tooling pipeline).
There are a few dependencies you need to consider when installing the Python module:
- for text extraction, filtering, and tokenization:
pip install datatrove[processing] - for S3 support:
pip install datatrove[s3] - for command-line tools:
pip install datatrove[cli]
One especially spiffy end-to-end ecxample is process_common_crawl_dump.py, which demonstrates a full pipeline to read common crawl WARC files, extract their text content, filter, and save the resulting data to S3
If you haven’t played with these before, they could save you quite a bit of time, even if you aren’t “doign AI”.
Envirowashing AI

AI tech is irrefutably accelerating the strain on natural resources, so it’s a bit difficult to feature an AI-based set of resources that — in part — makes it sound like AI is going to “save us”. But, this recent drop by Two Minute Papers did a decent enough job on the overview, that I grabbed the papers it covered (YouTube trackers removed from links):
- Flood forecasting:
- Weather forecasting:
- Sustainable flights:
and, can say, AI-enabled climate and travel optimization research does look very promising.
Google’s new AI system enhances flood prediction by reusing data from the USA and applying it to countries lacking such data. This fairly new approach bypasses the need for precise rainfall predictions, which are traditionally difficult to acquire in various regions. The new technique uses data from advanced nations to aid less developed countries, improving accuracy.
Another novel AI technique for weather prediction uses diffusion-based models, leveraging historical data to forecast extreme weather events. This method has proven more efficient and accurate than previous techniques, and operates at a fraction of the computational cost, potentially predicting and mitigating extreme weather effects.
And, another, alternative AI approach is seeking to make flights more sustainable by predicting and reducing the impact of aircraft contrails, which contribute to global warming. By adjusting flight paths slightly, the AI reduces contrail formation, cutting the heat-trapping effect by half with minimal additional fuel usage. This technique was successfully tested with American Airlines.
All three projects talk about “saving lives” and enabling “significant environmental benefits”.
O_O
Nice try!
Until organizations like Google, OpenAI, Microsoft, and more, stop trying to get us all to subscribe to their AI/AI-API taxes just to make their execs and billionaire mates even richer, it’s difficult to see how the offsets in these legitimate uses of AI will bear much fruit when we seem heck bent on chatting ourselves into extinction.
FIN
Remember, you can follow and interact with the full text of The Daily Drop’s free posts on Mastodon via @dailydrop.hrbrmstr.dev@dailydrop.hrbrmstr.dev ☮️

Leave a comment